


本研究運用多源數(shù)據(jù),借助CNN-LSTM-Attention的混合模型,對國債ETF價格漲跌的二分類問題進行預(yù)測,并通過系統(tǒng)的數(shù)據(jù)處理與特征工程,深入比較該混合模型與其他主流神經(jīng)網(wǎng)絡(luò)模型的性能表現(xiàn)。研究表明,混合模型在國債ETF預(yù)測精度方面有一定的優(yōu)勢,為后續(xù)AI賦能債券投資提供了參考依據(jù)。
關(guān)鍵詞
國債ETF 深度學(xué)習(xí) 多源數(shù)據(jù) 模型對比
引言
在金融科技蓬勃發(fā)展的浪潮中,以深度求索(DeepSeek)、ChatGPT為代表的大語言模型正迅速滲透到金融市場的各個角落,給傳統(tǒng)的金融證券投資領(lǐng)域帶來了前所未有的變革。這些模型憑借強大的自然語言處理能力和海量數(shù)據(jù)的學(xué)習(xí)能力,在投資策略制定、風(fēng)險評估等方面展現(xiàn)出巨大的潛力。
當(dāng)前,中國國債市場正處于一個特殊的發(fā)展階段,國債利率水平相對較低,靜態(tài)票息難以滿足投資者日益增長的收益需求。在此背景下,機構(gòu)投資者們不得不將目光轉(zhuǎn)向債券的波段交易,期望通過精準(zhǔn)把握國債等利率債品種價格的短期波動來實現(xiàn)收益的增厚。
隨著人工智能(AI)技術(shù)的飛速發(fā)展,深度學(xué)習(xí)模型在金融領(lǐng)域的應(yīng)用日益廣泛。卷積神經(jīng)網(wǎng)絡(luò)模型(CNN)、長短期記憶網(wǎng)絡(luò)模型(LSTM)、變換器模型(Transformer)等深度學(xué)習(xí)模型,以其強大的非線性擬合能力和對時間序列數(shù)據(jù)的處理能力,為國債 ETF 價格預(yù)測提供了全新的思路和方法。
本研究聚焦國債交易型開放式指數(shù)基金1(ETF,代碼 511010),通過整合宏觀經(jīng)濟數(shù)據(jù)、市場交易數(shù)據(jù)等多源信息,基于CNN-LSTM-Attention機制的混合模型,展開對國債ETF價格漲跌的預(yù)測研究,并將該混合模型與傳統(tǒng)的神經(jīng)網(wǎng)絡(luò)三大模型的預(yù)測性能進行深入細(xì)致的對比分析。本研究旨在為債券投資者提供具有實操性的科學(xué)指導(dǎo)。
數(shù)據(jù)處理與特征工程
(一)數(shù)據(jù)來源
1.國債ETF行情數(shù)據(jù)
筆者通過萬得(Wind)收集了2015年1月1日至2024年 12月31日期間國債ETF的每日行情數(shù)據(jù),包括開盤價、收盤價、最高價、最低價以及成交量等基礎(chǔ)信息。基于這些原始數(shù)據(jù),進一步衍生計算出如 OBV(能量潮指標(biāo))、MA5(5日移動平均線)、WR(威廉指標(biāo))等關(guān)鍵技術(shù)指標(biāo),以全面反映國債ETF的市場交易特征。
2.宏觀基本面數(shù)據(jù)以及資金指標(biāo)數(shù)據(jù)
筆者通過Wind收集了宏觀經(jīng)濟和資金指標(biāo)方面的數(shù)據(jù),如 國內(nèi)生產(chǎn)總值(GDP)、工業(yè)品出廠價格指數(shù)(PPI)、居民消費價格指數(shù)(CPI)、工業(yè)增加值同比增速、固定資產(chǎn)累計同比增速、出口同比增速、社會消費品零售總額同比增速、工業(yè)增加值累計同比增速、R007(銀行間市場7天回購利率)、DR007(存款類機構(gòu)間7天回購利率)等。考慮到部分宏觀指標(biāo)為季度或月度數(shù)據(jù),為與日度的國債ETF行情數(shù)據(jù)在時間維度上匹配,采用線性插值法將部分宏觀數(shù)據(jù)轉(zhuǎn)化為日度數(shù)據(jù),確保數(shù)據(jù)的一致性和可用性。
(二)數(shù)據(jù)預(yù)處理與特征工程
1.特征變量構(gòu)建
基于收集到的國債ETF行情數(shù)據(jù)、資金面指標(biāo)數(shù)據(jù)以及宏觀基本面數(shù)據(jù),初步構(gòu)建了備選特征向量集合。為了篩選出最具代表性、對預(yù)測結(jié)果貢獻最大的特征變量,運用數(shù)據(jù)可視化技術(shù)繪制了各特征變量間的相關(guān)系數(shù)熱力圖,直觀展示變量之間的線性相關(guān)性。相關(guān)系數(shù)熱力圖通過顏色深淺表示相關(guān)性的強弱,以快速識別出高度相關(guān)的特征變量。同時,通過隨機森林中的特征重要性分析算法生成特征變量重要性展示圖,量化評估每個特征的重要程度。綜合這兩種分析方法,我們能夠更全面地評估每個特征變量的相關(guān)性和重要性。最終確定了用于模型訓(xùn)練的核心特征變量,即features= [‘Volume’, ‘Cpi’, ‘Ppi’, ‘Export_rate’, ‘RetailSale’, ‘M2’, ‘R007’, ‘WR’, ‘OBV’]。這些特征變量在相關(guān)系數(shù)熱力圖中表現(xiàn)出較低的多重共線性,同時在特征重要性展示圖中有較高的重要性得分,從而確保了模型的穩(wěn)定性和預(yù)測性能。各備選特征變量之間的相關(guān)系數(shù)及重要程度見圖1、圖2。


2.標(biāo)簽設(shè)置背景與處理
鑒于實際投資過程中,預(yù)測國債ETF是為進一步構(gòu)建證券量化投資策略提供決策依據(jù),因此預(yù)測漲跌的二分類問題要比預(yù)測具體數(shù)值更具有實操意義。當(dāng)國債ETF下一日的收盤價較當(dāng)日上漲時,標(biāo)簽賦值1;否則,賦值0。
3.金融時間序列非平穩(wěn)性處理
鑒于金融時間序列普遍存在的非平穩(wěn)性,直接使用原始數(shù)據(jù)可能導(dǎo)致模型訓(xùn)練效果不佳。為了消除數(shù)據(jù)中的趨勢和季節(jié)性因素,使數(shù)據(jù)滿足平穩(wěn)性假設(shè),對選定的特征變量進行了差分處理。通過差分操作,有效提取了數(shù)據(jù)的動態(tài)變化特征,為后續(xù)的模型訓(xùn)練提供了更優(yōu)質(zhì)的數(shù)據(jù)基礎(chǔ)。
模型構(gòu)建與訓(xùn)練
(一)一維CNN
一維CNN(1D-CNN)在處理時間序列數(shù)據(jù)時,能夠通過卷積核在時間維度上的滑動,高效提取數(shù)據(jù)的局部特征。
該模型包含多個卷積層和池化層。卷積層通過不同大小的卷積核進行卷積操作,提取數(shù)據(jù)的局部模式和特征;池化層則對卷積層的輸出進行降維處理,減少計算量,同時保留關(guān)鍵特征。本研究中,模型輸入時間步長為20的9個特征變量數(shù)據(jù),經(jīng)過多個卷積層和池化層的特征提取后,通過全連接層進行分類預(yù)測,最終輸出預(yù)測結(jié)果。訓(xùn)練過程中,使用Adam優(yōu)化器和交叉熵?fù)p失函數(shù),以優(yōu)化模型參數(shù),提高預(yù)測準(zhǔn)確性。
(二)LSTM
LSTM作為一種特殊的循環(huán)神經(jīng)網(wǎng)絡(luò),具備強大的處理時間序列數(shù)據(jù)中長期依賴關(guān)系的能力,其核心思想是通過門控機制和記憶單元控制信息流動,既能捕捉短期特征,又能保留長期依賴關(guān)系。本研究中,構(gòu)建的LSTM模型每個樣本包含過去20個時間步的9個特征變量數(shù)據(jù)。模型結(jié)構(gòu)包括LSTM層、隱藏層和全連接輸出層。LSTM層及隱藏層通過門控機制,選擇性地保留時間序列中的關(guān)鍵信息;全連接層則將LSTM隱藏層的輸出映射到預(yù)測結(jié)果空間。模型訓(xùn)練采用Adam優(yōu)化器,該優(yōu)化器能夠自適應(yīng)調(diào)整學(xué)習(xí)率,加快模型收斂速度;損失函數(shù)選用交叉熵?fù)p失函數(shù),用于衡量模型預(yù)測結(jié)果與真實標(biāo)簽之間的差異。
(三)Transformer
Transformer基于自身注意力機制,打破了傳統(tǒng)循環(huán)神經(jīng)網(wǎng)絡(luò)和卷積神經(jīng)網(wǎng)絡(luò)在處理長序列數(shù)據(jù)時的局限性,能夠更有效地捕捉序列數(shù)據(jù)中的全局依賴關(guān)系。在本研究中,構(gòu)建的Transformer包含多個多頭注意力層和前饋神經(jīng)網(wǎng)絡(luò)層。通過多個注意力頭并行計算,從不同角度捕捉數(shù)據(jù)的依賴關(guān)系;最后經(jīng)過前饋神經(jīng)網(wǎng)絡(luò)層進行特征變換和映射,通過全連接層輸出預(yù)測結(jié)果。模型訓(xùn)練采用Adam優(yōu)化器和交叉熵?fù)p失函數(shù),確保模型在訓(xùn)練過程中不斷優(yōu)化,提升預(yù)測性能。
(四)基于CNN-LSTM-Attention的混合模型
本研究借鑒了Transformer中極具創(chuàng)新性的Attention機制,該機制依據(jù)時間步重要性動態(tài)分配權(quán)重,提升對重要信息的關(guān)注度與預(yù)測準(zhǔn)確性。基于CNN-LSTM-Attention的混合模型,融合多種神經(jīng)網(wǎng)絡(luò)優(yōu)勢,處理復(fù)雜時間序列數(shù)據(jù)時優(yōu)勢顯著。CNN利用局部感受野和權(quán)值共享,能自動提取國債ETF數(shù)據(jù)中的價格短期波動、成交量變化等局部特征,為后續(xù)分析筑牢根基;LSTM憑借門控機制,既能銘記長期經(jīng)濟因素影響下的價格走勢,又能對短期波動迅速作出反應(yīng),精準(zhǔn)把握價格長期趨勢與動態(tài)變化。三者結(jié)合賦予模型靈活性與適應(yīng)性,面對復(fù)雜的市場環(huán)境,能有效處理各類關(guān)鍵信息,維持良好性能。
(五)模型訓(xùn)練與評估
將經(jīng)過處理的數(shù)據(jù)按照80%、20%的比例劃分為訓(xùn)練集、驗證集。訓(xùn)練集用于模型參數(shù)的學(xué)習(xí)和優(yōu)化,加入丟棄層(Dropout)防止過擬合現(xiàn)象的發(fā)生;測試集則用于評估模型的最終性能。在訓(xùn)練過程中,通過調(diào)整模型的超參數(shù),如學(xué)習(xí)率、隱藏層節(jié)點數(shù)等,觀察測試集上的性能指標(biāo)變化,選擇性能最優(yōu)的模型參數(shù)配置。訓(xùn)練完成后,使用測試集對3個模型進行全面評估,主要評估指標(biāo)包括受試者工作特征曲線(ROC曲線)、精度和損失等。ROC 曲線則從分類閾值的角度,綜合評估模型的分類性能;精度和損失分別衡量模型預(yù)測的準(zhǔn)確性和誤差程度。
實驗結(jié)果與分析
(一)模型性能對比
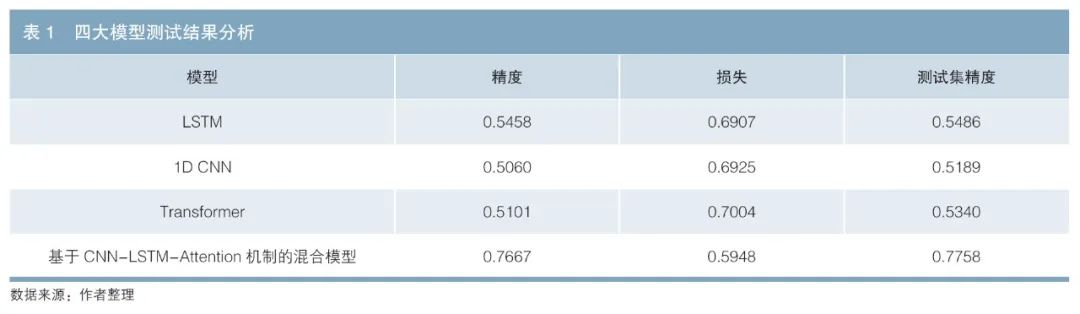
通過在測試集上的實驗,得到了4個模型的ROC 曲線以及精度和損失等關(guān)鍵指標(biāo)。本文中,模型的損失函數(shù)采用的是交叉熵?fù)p失,用于衡量模型預(yù)測值與真實標(biāo)簽之間的差異。交叉熵?fù)p失函數(shù)是一種常用于分類任務(wù)的損失函數(shù),特別是在二分類問題中。其衡量的是模型預(yù)測值(概率分布)與真實標(biāo)簽(概率分布)之間的差異。交叉熵?fù)p失越小,表示模型的預(yù)測值越接近真實值。精度定義為模型預(yù)測正確的樣本數(shù)占總樣本數(shù)的比例,測試集精度則是模型在測試集上的預(yù)測精度,用于評估模型的泛化能力。實驗結(jié)果表明,基于CNN-LSTM-Attention的混合模型在精度和測試集精度方面均顯著優(yōu)于1D-CNN、LSTM以及Transformer,損失相對較低(見表1)。
(二)ROC 曲線分析
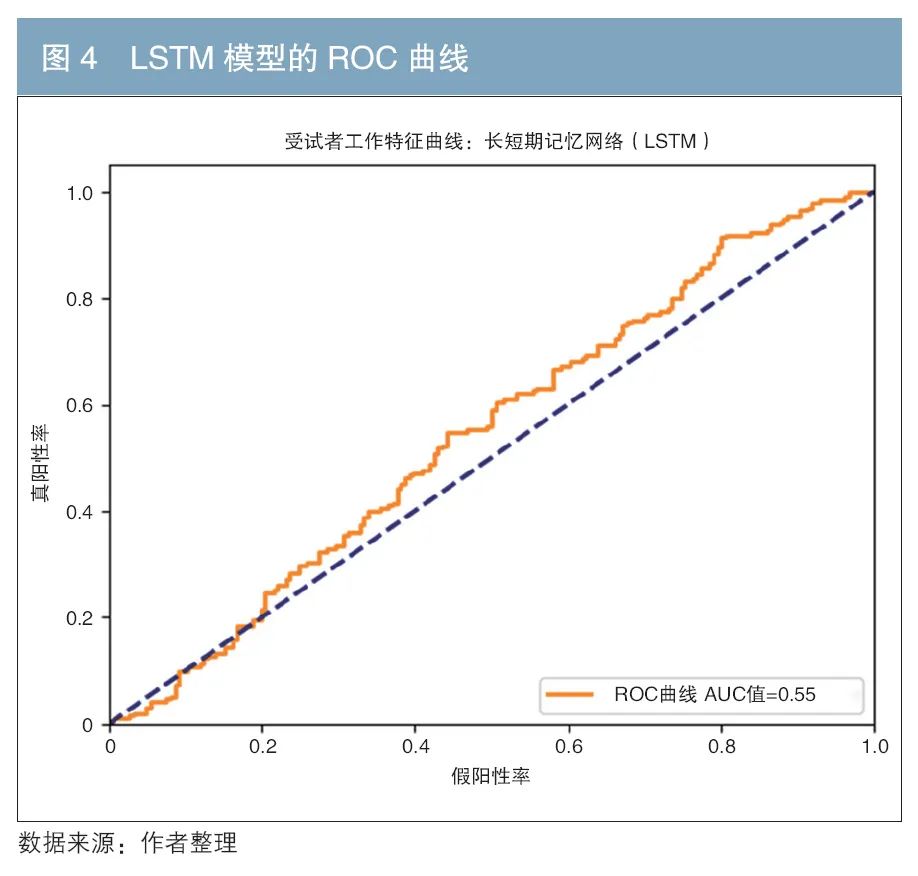
ROC曲線是一種用于評估二分類模型性能的工具,其以真正率(True Positive Rate,TPR,即實際正例中被正確預(yù)測為正例的比例)為縱軸,假正率(False Positive Rate,F(xiàn)PR,即實際負(fù)例中被錯誤預(yù)測為正例的比例)為橫軸。通過繪制不同分類閾值下的TPR和FPR,可以直觀地展示模型在不同判斷標(biāo)準(zhǔn)下區(qū)分正例和負(fù)例的能力。從4種模型的ROC曲線來看,曲線下面積值(AUC)均位于0.5~0.56,較為接近;ROC 曲線和AUC是評估二分類模型性能的重要工具,AUC 越接近 1,模型性能越好。結(jié)合表1數(shù)據(jù)來看,混合模型在測試集精度(0.7758)和整體精度(0.7667)上顯著優(yōu)于其他模型,但 AUC最小(0.54),這主要是因為測試集樣本(1類和0類)分布不均衡。雖然混合模型的AUC值相對較低,但其在測試集精度和整體精度上顯著優(yōu)于其他模型。這表明混合模型在特定分類閾值下具有較高的預(yù)測準(zhǔn)確性,但在整體分類閾值范圍內(nèi)表現(xiàn)不夠穩(wěn)定。未來的研究可以進一步優(yōu)化模型的分類閾值選擇,以提高AUC值。4種模型的ROC曲線如圖3—圖6所示。



結(jié)論與改進建議
(一)結(jié)論
在利用多源數(shù)據(jù)進行國債ETF漲跌預(yù)測的任務(wù)中,基于CNN-LSTM-Attention的混合模型憑借其獨特的結(jié)構(gòu)和強大的時間序列處理能力,在精度、損失和驗證集精度等關(guān)鍵性能指標(biāo)上均表現(xiàn)出色,顯著優(yōu)于1D-CNN模型、LSTM模型和Transformer模型,展現(xiàn)出更為卓越的預(yù)測性能。
本研究充分凸顯了人工智能技術(shù)在債券投資領(lǐng)域的巨大潛力,為債券投資實踐提供了全新的視角和方法。未來的研究可以在現(xiàn)有基礎(chǔ)上,進一步拓展數(shù)據(jù)來源,優(yōu)化模型結(jié)構(gòu),探索更有效的特征工程方法,以不斷提升國債ETF漲跌預(yù)測的準(zhǔn)確性和穩(wěn)定性。
(二)改進建議
數(shù)據(jù)方面:在金融市場環(huán)境日益復(fù)雜且動態(tài)變化的背景下,準(zhǔn)確預(yù)測國債ETF的走勢成為極具價值與挑戰(zhàn)的研究課題。盡管本研究已使用國債ETF行情數(shù)據(jù)與宏觀基本面數(shù)據(jù),但目前的研究尚未充分考量貨幣政策等非結(jié)構(gòu)化數(shù)據(jù),而這類數(shù)據(jù)在國債ETF市場中扮演著舉足輕重的角色。未來可進一步通過自然語言處理(NLP)算法處理貨幣政策執(zhí)行報告與貨幣政策會議紀(jì)要得到貨幣態(tài)度指數(shù)等指標(biāo)。同時,在數(shù)據(jù)處理環(huán)節(jié),進一步優(yōu)化對缺失數(shù)據(jù)的處理方法,后續(xù)將嘗試基于機器學(xué)習(xí)的缺失值預(yù)測算法,如 K 近鄰算法、決策樹算法等,利用數(shù)據(jù)之間的內(nèi)在關(guān)系和模式,更準(zhǔn)確地預(yù)測缺失值,提升數(shù)據(jù)質(zhì)量。另外,針對測試集樣本(1類和0類)分布不均衡的問題,后續(xù)會進一步研究重采樣的處理方法。
模型方面:深度學(xué)習(xí)模型本質(zhì)上是通過對歷史數(shù)據(jù)進行近似的非線性映射來實現(xiàn)預(yù)測。然而,金融市場中諸如政策發(fā)布、突發(fā)事件沖擊等動態(tài)變化因素,極易導(dǎo)致預(yù)測結(jié)果出現(xiàn)偏差。因此,為確保模型的預(yù)測精度,需定期對模型重新進行訓(xùn)練,并及時更新模型參數(shù)。
特征工程方面:在現(xiàn)有特征選擇基礎(chǔ)上,運用更復(fù)雜、更先進的特征選擇算法,如基于樹模型的特征選擇方法、XGBoost的特征得分等,這些方法能夠更精準(zhǔn)地篩選出對模型預(yù)測結(jié)果貢獻最大的關(guān)鍵特征,減少冗余特征對模型性能的干擾。同時,嘗試生成新的特征,結(jié)合技術(shù)分析與基本面分析,創(chuàng)造如宏觀指標(biāo)與技術(shù)指標(biāo)的交叉特征,如將GDP增速與OBV指標(biāo)進行組合,構(gòu)建新的特征變量,增強模型對國債ETF漲跌規(guī)律的捕捉能力。
注:
1.代碼為511010。
參考文獻
[1] Bengio Y, Simard P, Frasconi P. Learning long-term dependencies with gradient descent is difficult[J]. IEEE Transactions on Neural Networks, 1994, 5(2).
[2] Box G E P, Jenkins G M, Reinsel G C, et al. Time Series Analysis: Forecasting and Control[M]. Hoboken, NJ: John Wiley & Sons, 2015.
[3] Chen T, Guestrin C. XGBoost: A Scalable Tree Boosting System[C]//Proceedings of the 22nd ACM SIGKDD International Conference on Knowledge Discovery and Data Mining (KDD). New York, NY: ACM, 2016.
[4] Chen X, Hu W. Attention-based LSTM-CNN for Stock Market Prediction[C]//Proceedings of the 2018 IEEE International Conference on Data Mining (ICDM). Piscataway, NJ: IEEE, 2018.
[5] Fawcett T. An Introduction to ROC Analysis[J]. Pattern Recognition Letters, 2006, 27(8).
[6] Hochreiter S, Schmidhuber J. Long Short-Term Memory[J]. Neural Computation, 1997, 9(8).
[7] LeCun Y, Bengio Y, Haffner P. Gradient-based learning applied to document recognition[J]. Proceedings of the IEEE, 1998, 86(11).
[8] Rumelhart D E, Hinton G E, Williams R J. Learning Representations by Back-propagating Errors[J]. Nature, 1986, 323(6088).
[9] Wang Z, Oates T. Imaging Time-Series to Improve Classification and Imputation[EB/OL]. arXiv preprint arXiv: 1506.00321, 2015.

責(zé)任編輯:趙思遠(yuǎn)




VIP課程推薦
APP專享直播
熱門推薦
收起公眾號")
24小時滾動播報最新的財經(jīng)資訊和視頻,更多粉絲福利掃描二維碼關(guān)注(sinafinance)




