


從爆料中可以看出,RL尚處早期,性能提升遠未見頂;跨領域測試泛化能力,拒絕“記憶投機”;從語言模型到數學證明,RL正向高階推理邁進。
剛剛我注意到DeepSeek研究員Daya Guo回復了網友有關DeepSeek R1的一些問題,以及接下來的公司的計劃,只能說DeepSeek的R1僅僅只是開始,內部研究還在快速推進,DeepSeek 的研究員過年都沒歇,一直在爆肝推進研究,接下來DeepSeek還有大招
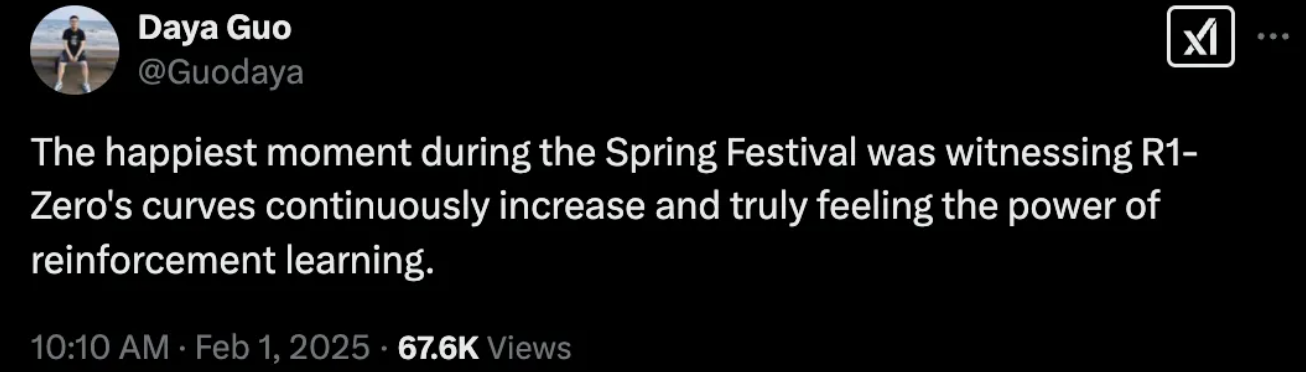
事情是這樣的,2月1號,大年初四Daya Guo發了一條推文,透露了春節期間讓他最興奮的事情,親眼見證了?R1-Zero?模型性能曲線的?“持續增長”,并且直言感受到了?強化學習(RL)的強大力量!這一下子就點燃了網友們的好奇心,大家紛紛跑去圍觀提問(太拼了,deepseek研究員過年都在爆肝訓練模型)
以下我來幫大家還原一下Daya Guo與網友對話:
網友A @PseudoProphet:?“大佬,想問下這個性能持續提升能持續多久呢?現在是早期階段嗎?感覺DeepSeek的RL模型是不是像語言模型里的GPT-2一樣剛起步?還是說已經到GPT-3.5那種比較成熟的階段,快要遇到瓶頸了?”
這個問題問的相當犀利啊,直接關系到DeepSeek RL技術的潛力!Daya Guo 的回復也十分坦誠:
Daya Guo :?“我覺得我們還處于非常早期的階段,RL 領域還有很長的路要探索。但我相信今年會看到顯著的進展”
劃重點!?“非常早期”,?“很長的路要探索”,?“今年會有顯著進展”!這幾個關鍵詞信息量巨大。這意味著,DeepSeek 認為他們在RL領域仍然有巨大的進步空間,R1 現在的成績可能只是冰山一角,未來可期啊!
緊接著,另一位網友 @kaush_trip (Cheeku Tripathi)拋出了一個更專業的問題,直擊模型能力的核心:
網友B @kaush_trip:?“基于 R1-Zero 的性能,您如何評估模型是真的具備了?泛化能力,還是僅僅?記憶了狀態轉換和獎勵??”
這個問題問的非常到位!畢竟現在很多模型看起來很強大,但實際上只是在訓練數據上“死記硬背”,換個環境就拉胯。DeepSeek R1 到底是不是真材實料呢?
Daya Guo :?“我們使用?RL prompt 未覆蓋的領域的基準?來評估泛化能力。目前來看,它?似乎具備泛化能力”
“RL prompt 未覆蓋的領域” 這句話是關鍵!這意味著 DeepSeek 不是用訓練數據來“作弊”評估,而是用模型?從未見過?的新場景來測試,這才能真正體現模型的泛化水平。Daya Guo 用 “似乎具備” 這種嚴謹的措辭,也更顯得真實可信
接下來,一位ID名為 @teortaxesTex 的網友,DeepSeek的忠實粉絲(備注里都寫著“DeepSeek鯨魚啦啦隊”),他從DeepSeek V3 技術報告入手,提出了一個關于?模型訓練時間?的問題:
網友C @teortaxesTex:?“如果不是秘密的話:這次 RL 訓練跑了多久?感覺你們早在 12 月 10 號就有了 R1 或者至少是 R1-Zero,因為 V3 技術報告里提到 V2.5 模型用了 R1 的知識蒸餾,而且 V2.5-1210 的分數和現在的模型一樣。現在做的這個是那次訓練的延續嗎?”
這位網友觀察力驚人啊!能從技術報告里摳出這么多細節。Daya Guo 也耐心解答了模型的迭代過程:
Daya Guo :?“660B 參數的 R1-Zero 和 R1 是在 V3 發布之后才開始跑的,訓練大約花了?2-3 周。之前我們提到的 R1 模型(比如在 V3 技術報告里),實際上是?R1-Lite 或者 R1-Lite-Zero”
原來如此!我們現在看到的 R1-Zero 和 R1 是 “全新升級版”,之前的 R1-Lite 系列是小規模版本。看來 DeepSeek 在背后默默迭代升級了不少版本啊
關于訓練速度,網友 @jiayi_pirate (Jiayi Pan)和 網友B @kaush_trip 又接力提出了一個“靈魂拷問”:
網友D @jiayi_pirate:?“3 周 1 萬 RL steps,每個梯度傳播 (grpo) 步驟要 ~ 3 分鐘 ????”
網友B @kaush_trip:?“如果每個梯度傳播 (grpo) 步驟要 ~3 分鐘,那大概每小時 5 步,每天 120 步,確實很慢。”
這算的是真夠細致的!按照網友的計算,DeepSeek R1 的訓練速度確實不算快。側面也說明,這種高性能的 RL 模型,訓練成本和時間投入都是巨大的。“慢工出細活” 用來形容 AI 模型訓練,好像也挺合適的
最后,一位名叫 @davikrehalt (Andy Jiang)的網友,從更前沿的應用角度提了一個問題:
網友E @davikrehalt:?“你們有沒有嘗試用 RL 來搞?形式化證明環境,而不是只做問答對?要是今年有個開源模型能在 IMO (國際數學奧林匹克) 拿金牌就好了!(以及更多希望!)”
形式化證明!IMO 金牌!這位網友的野心不小啊!不過,把 AI 應用到數學證明這種硬核領域,確實是未來趨勢。Daya Guo 的回答再次讓人驚喜:
Daya Guo :?“我們也在嘗試將 R1 應用于?Lean?這樣的形式化證明環境。我們希望盡快向社區發布更好的模型”
聽 Daya Guo 的意思,他們在這方面已經有進展,未來可能會有更重磅的模型發布!期待值拉滿!
寫在最后
從Daya Guo的回應中可提煉三大信號:
技術定位:RL尚處早期,性能提升遠未見頂;
驗證邏輯:跨領域測試泛化能力,拒絕“記憶投機”
應用邊界:從語言模型到數學證明,RL正向高階推理邁進
本文來源:AI寒武紀,原文標題:《最新!DeepSeek研究員在線爆料:R1訓練僅用兩到三周,春節期間觀察到R1 zero強大進化》
風險提示及免責條款
市場有風險,投資需謹慎。本文不構成個人投資建議,也未考慮到個別用戶特殊的投資目標、財務狀況或需要。用戶應考慮本文中的任何意見、觀點或結論是否符合其特定狀況。據此投資,責任自負。


VIP課程推薦
APP專享直播
熱門推薦
收起
24小時滾動播報最新的財經資訊和視頻,更多粉絲福利掃描二維碼關注(sinafinance)




